
4.2 Herramientas para los análisis reproducibles
Generalmente, cuando se habla de reproducibilidad se toma en consideración su dimensión computacional, esto es, el trabajo con código. Como investigadores de las ciencias sociales empíricas y promotores de la ciencia abierta creemos que efectivamente este es el núcleo de la reproducibilidad, sin embargo no es su única acepción. La mera existencia de un código de análisis no nos garantiza que un proyecto sea reproducible per se, dado que es importante tener en consideración cómo es que distintos elementos del proyecto se relacionan entre sí para regenerar los resultados de un trabajo publicado. Considerando esto, es que dividiremos esta sección presentando un flujo de trabajo reproducible con cuatro características:
- Estructura del proyecto
- Documentos dinámicos
- Control de versiones
- Prácticas de código
Veamos cada uno de ellos.
4.2.1 Estructura del proyecto
Una de las principales cosas que debemos considerar al elaborar un proyecto es su estructura de carpetas y archivos, con el fin de que esta nos permita entender e identificar los archivos existentes y rol en el flujo de trabajo. En este sentido, una de las herramientas que han sido desarrolladas son los denominados Protocolos (p. ej. TIER, DRESS, IPO), los cuales brindan una serie de orientaciones referentes a estructura digital de carpetas, documentación de archivos y rutinas para conseguir el anhelado objetivo de los análisis reproducibles. Para esto, es posible mencionar una serie de orientaciones generales referentes a dichos procedimientos, por ejemplo en el Proyecto TIER (TIER, 2020) se han desarrollado protocolos orientados a la reproducibilidad de los análisis, los cuales se fundamentan en tres principios que se describen a continuación.
Reproducibilidad: La documentación debe permitir regenerar completamente los resultados del estudio original. En primer lugar, se debe comenzar con los datos originales brutos idénticos a aquellos con los que el autor comenzó la investigación. Luego, la posibilidad de realizar las mismas rutinas de código para preparar los datos finales para el análisis. Finalmente, se debe disponer de las rutinas de código que permitan regenerar los mismos resultados publicados, por ejemplo, las tablas o figuras presentes en la investigación.
Independencia: Toda la información necesaria para regenerar los resultados del estudio debe estar presente en la documentación. Esto refiere a que no debe ser necesario solicitar ninguna información adicional al autor original.
Realismo: La documentación debe estar organizada y presentada con suficiente claridad para que bajo un criterio realista, sea factible que un investigador independiente con un nivel de expertise razonable tenga la posibilidad de regenerar completa e independientemente los resultados del estudio sin mayores dificultades.
Teniendo en cuenta lo anterior, la forma en que se encuentran organizadas las partes de un proyecto es fundamental para cumplir a cabalidad con lo que se propone cada principio. Como vimos en la sección previa, es posible entender la reproducibilidad como un espectro que involucra una tríada de tres elementos: Datos, Métodos y Resultados.
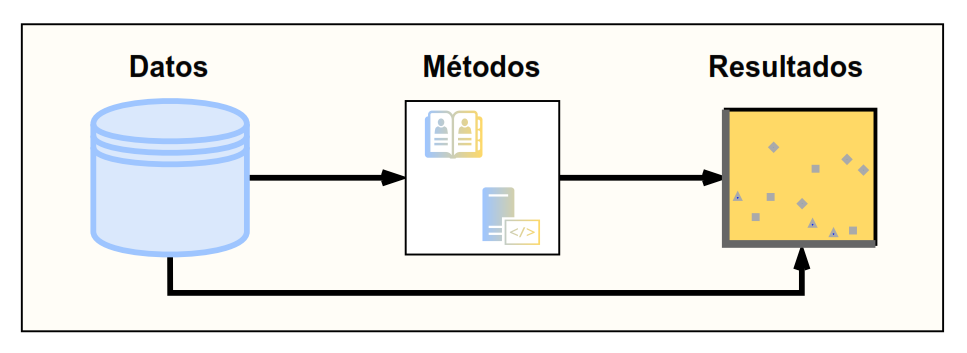
Figura 4.1: Flujo de trabajo reproducible.
Este esquema es una síntesis que hacemos de algunos de los protocolos más usados en las ciencias sociales. Más que proponer un protocolo nuevo, buscamos describir los elementos fundamentales que contiene una estructura de proyecto reproducible y que están presentes de alguna u otra forma en la mayoría de los protocolos.
4.2.1.1 Carpeta raíz
Antes de detallar los tres elementos que se deben considerar para avanzar en el espectro de reproducibilidad, es importante partir de una base. Esta es la que en distintos protocolos y otras herramientas para la reproducibilidad se conoce como la carpeta raíz (root). La carpeta raíz es donde se alberga toda la documentación de referencia general para el proyecto, lo que abarca desde bases de datos hasta el cuestionario u otros documentos similares. La carpeta raíz es el punto de partida para poder emplear otras prácticas para la reproducibilidad.
A modo de ir avanzando en el espectro de reproducibilidad, es importante tener en consideración dos principios en relación con la carpeta raíz: documentar y orientar. La documentación implica exponer ordenadamente el contenido del proyecto completo de manera jerárquica, es decir, el contenido de subcarpetas y su funciones. En cambio, orientar implica conducir una correcta ejecución de las rutinas que permitan regenerar los resultados de la investigación. Una carpeta base que logre considerar estos principios debe tener los siguientes contenidos:
Detalle de la base y las subcarpetas organizadas según su contenido. Una manera amigable de representar esta estructura es a través de un “árbol de directorios”, el cual ilustra la jerarquía de las carpetas y los principales archivos contenidos.
Instrucciones para la configuración del paquete estadístico necesario para ejecutar las rutinas de código. Esto considera el número de versión del software, los complementos necesarios que sean adicionales al paquete estándar y cualquier otra información especial sobre el software que el lector necesite conocer para reproducir los resultados del estudio.
Instrucciones de “inicio-a-fin” para regenerar los resultados a través de referencias directas al uso de los archivos de procesamiento de datos en la preparación y análisis. En este apartado se deben incluir detalladamente los objetivos de cada rutina de código de manera independiente.
Los contenidos descritos se deben incluir en un archivo que lleve de nombre “readme.md/txt/pdf”. Una sugerencia de estructura interna de este documento es la siguiente:
- Estructura y contenido del proyecto reproducible
- Esquema tipo “Árbol de directorios”
- Descripción de cada subcarpeta, sus archivo y roles
- Instrucciones y rutinas de ejecución de resultados
- Instrucciones para configuración del software
- Instrucciones para la ejecución de rutinas de código de “inicio-a-fin”
Con este archivo “readme.md/txt/pdf” ya contamos con el primer gran paso hacia la reproducibilidad: nuestra carpeta raíz está bien documentada y logra orientar bien a cualquier tercero que quiera reproducir nuestra investigación. Con esto descrito, pasaremos a detallar los tres elementos a considerar para adoptar un enfoque reproducible en un proyecto (Datos-Método-Resultados)
4.2.1.2 Datos
En la ciencia trabajamos con datos, ya sean cualitativos o cuantitativos, primarios o secundarios. Si nos desempeñamos como científicos analizaremos datos con tal de sacar conclusiones relevantes para el avance del conocimiento. Es por esto que el cómo albergamos y documentamos los datos para nuestro estudio es uno de los primeros puntos a considerar para adoptar un enfoque orientado hacia la reproducibilidad. El objetivo es que cualquier persona sea capaz de comprender nuestros datos y utilizarlos para reproducir nuestros análisis.
Si bien los protocolos varían de acuerdo a cómo se organizan los datos dentro de la carpeta raíz (i.e. en qué carpeta se alojan), algo que suele ser común entre los protocolos y que es relevante de recalcar acá es la diferenciación entre los datos originales o “crudos” (raw data) y los datos procesados. Los datos originales son aquellos que no han sufrido ningún tipo de modificación, en contraste a los datos procesados. El albergar ambas bases de datos permite comprender de mejor forma las modificaciones que se hicieron y las decisiones que se tomaron.
Al igual que con la carpeta raíz, sugerimos ciertas prácticas de documentación y orientación para que el proyecto sea reproducible. Presentamos el detalle para los datos originales y los datos procesados.
Para toda fuente de datos original, se debe proveer la siguiente información:
Citación bibliográfica en un formato estándar (p. ej. American Psychological Association, Chicago, etc). Sugerimos revisar el componente de “Datos Abiertos” para la publicación de datos.
La fecha de creación de la base de datos o el día en que se accedió por primera vez por parte del autor (en caso de que sean datos secundarios).
Una descripción respecto a cómo se puede acceder a una copia de esta base de datos. Se debe ser lo suficientemente claro como para que un usuario independiente pueda acceder a los datos sin requerir información adicional.
Un libro de códigos de todas las variables de la base de datos. Sugerimos revisar el apartado “¿Cómo hacer un libro de códigos?”.
Para toda fuente de datos procesada, es posible identificar dos tipos:
Base de datos intermedia, la cual contiene información que, por un lado, puede ser complementaria con una base de datos principal. Por ejemplo, tenemos una base de datos con información de individuos pertenecientes a zonas/territorios (regiones o países), a la cual necesitamos incorporar información adicional que proviene de fuentes externas. En este caso, podemos generar una base procesada intermedia, para luego proceder a combinar ambas fuentes de datos.
Base de datos final, es una versión final de una base de datos que contiene las variables completamente procesadas para realizar los análisis.
En estos casos se sugiere proveer la siguiente información:
- Libro de códigos de la base procesada. Para ello, las variables deben estar correctamente etiquetadas.
- Fecha de creación y versión de la base de datos procesada.
4.2.1.3 Métodos
Con los métodos nos referimos a toda información del proyecto relacionada al trabajo con los datos, específicamente al procesamiento y el análisis de datos. Ambas actividades pueden ser albergadas en un mismo archivo, no obstante e independiente del protocolo que se use, sugerimos separar ambas actividades en documentos distintos. Esto hará mucho más fácil la lectura del proceso de toma de decisiones, especialmente si son archivos de código. De esta manera, cualquier tercero podrá entender el proceso, evitando lo más posible que emerjan preguntas tipo ¿y de dónde salió esta variable?. En esta sección presentamos un flujo tanto para el documento de procesamiento como para el de análisis. Independiente del software estadístico que usted esté utilizando, será capaz de adherir a este flujo para hacer estas actividades de forma más ordenada.
El procesamiento de los datos cumple una función muy importante para el desarrollo de un artículo: la de procesar los datos que darán paso a los análisis del estudio. Considerando eso, el objetivo final de este documento es generar una base de datos procesada, que contenga solamente los datos importantes para analizar. El flujo puede ser:
Cargar la base de datos original: Cargar la base de datos original es el punto de partida para el procesamiento de los datos, y como tal, es muy importante que esta acción sea reproducible. En softwares como R, podemos hacer esta acción de manera reproducible al cargar los datos directamente de la web. Si esta no es una opción, podemos dejar bien documentado la forma en que se debe cargar la base de datos.
Revisar la base de datos: Una vez cargada la base de datos original, recomendamos siempre revisar para que todo esté en orden. Cuando decimos “ver que todo esté en orden” nos referimos a diagnosticar si la base ha sido correctamente cargada. Por ejemplo, a veces podría suceder que la base de datos está en formato .csv con las columnas separadas por punto y coma (“;”) y nosotros la cargamos en el formato tradicional (“,”).
Seleccionar las variables que se utilizarán: Generalmente no ocupamos todas las variables dentro de una base de datos, en especial en la investigación basada en encuestas con datos secundarios. Es por eso que el comienzo del procesamiento de datos consta de seleccionar las variables que utilizaremos para los análisis.
Renombrar las variables: Si bien no es estrictamente necesario renombrar las variables, sí se recomienda para facilitar tanto el propio trabajo cómo el de alguien que vaya a emplear el mismo código. Generalmente, en la investigación de encuestas con datos secundarios nos encontramos con grandes bases de datos, con nombres técnicos y poco autoexplicativos. La principal recomendación aquí es cambiar estos nombres por nombres cortos y autoexplicativos.
Procedimientos a realizar por cada variable:
Una vez hemos cumplido con los aspectos generales del procesamiento, podemos pasar a la revisión de variable a variable. Aquí proponemos el siguiente flujo:
Descriptivo inicial: calcular una tabla de frecuencias o de medidas de tendencia central y dispersión para conocer el estado de la variable previo a cualquier modificación.
Recodificación: aquí se toman las decisiones respecto a la recodificación de los datos perdidos y otro tipo de valores a modificar (e.g. errores de tipeo). Es importante que las decisiones sobre la recodificación queden bien estipuladas y transparentadas. Por ejemplo, en caso de hacer imputación en alguna variable, dejarlo comentado en el código.
Etiquetado: el etiquetado es una forma simple y eficiente de poder dar más información acerca de una variable. En el caso de bases de datos sobre encuestas, generalmente una base bien documentada trae etiquetas predeterminadas que hacen alusión a las preguntas del cuestionario. Es importante tener en consideración que no todos los softwares soportan el etiquetado en las bases de datos, en esos casos es útil elaborar un libro de códigos para nuestra base de datos procesada.
Descriptivo final: recomendamos que, posterior a haber hecho las recodificaciones correspondientes, revisar de nuevo las frecuencias o las medidas de tendencia central de las variables, para diagnosticar que no hemos cometido errores en el procesamiento. Por dar un ejemplo, un error común, es etiquetar mal las categorías de la variable, lo que tendría un impacto directo en la interpretación de los datos.
Otros ajustes: en esta última parte del flujo por variable, recomendamos efectuar toda modificación específica y relevante para la forma que analizaremos los datos. Por ejemplo, si fuésemos a construir un índice con algunas de las variables.
El seguir este flujo de manera sistemática facilitará la lectura tanto para terceros, como para nosotros mismos en el futuro.
Una vez contamos con nuestra base de datos procesada podemos analizar los datos. En el documento de análisis de datos se procede a elaborar todas las tablas, gráficos, pruebas estadísticas etc. que vayan a ser introducidos en el artículo final. Es importante que se piense en este documento como un reporte de análisis en sí mismo, es decir, debe estar dirigido al público y no solo ser un documento de trabajo interno para el equipo de investigación.
Al igual que para la sección de procesamiento de datos, aquí también recomendamos un flujo de trabajo para hacer el trabajo -y el código- reproducible y eficiente. Dividimos el flujo en dos secciones, primero, una que contenga los análisis necesarios para probar las hipótesis de investigación. Segundo, una sección con análisis secundarios y/o exploratorios que sean relevantes para lo que el artículo busca plantear.
- Efectuar análisis descriptivos univariados de los datos. Es ideal una tabla única que sintetice el comportamiento de las variables de interés.
- Efectuar análisis correlacional de los datos. Es una primera aproximación a las hipótesis, además de ser esquemático. Por ejemplo, el uso de matrices de correlación o de nubes de puntos.
- Efectuar análisis multivariados. Modelos que suelen ser la principal herramienta para poner a prueba las hipótesis.
- Efectuar análisis exploratorios. Esto en el caso que se quieran explorar relaciones o patrones que no fueron previamente hipotetizados.
Documentación
Para una correcta comprensión de los documentos de procesamiento y análisis es importante tener una descripción adecuada de cada una de sus partes, o dicho de otra forma, una correcta documentación. Es relevante precisar de qué manera estos documentos se vinculan con otros archivos dentro del proyecto, para lo cual podemos tomar el ejemplo del Protocolo IPO. Por un lado, el documento de preparación requiere de una fuente de datos inicial, por tanto está directamente relacionada con la carpeta Input y la subcarpeta de datos originales. Por otro lado, el documento de análisis requiere de una fuente de datos procesada, por tanto está directamente relacionada con la carpeta Input y la subcarpeta de datos procesados.
Para una correcta ejecución de las rutinas de código, es importante describir adecuadamente la relación entre los archivos de preparación y análisis. Para ello, se sugiere incorporar un archivo de nombre “readme-proc.md/txt/pdf”, en donde se describa brevemente dicha vinculación. Para ello sugerimos los siguientes puntos a describir:
- Para la ejecución de la preparación, precisar la ubicación de la o las fuentes de datos originales. (p.ej. “input/data/original/original-data.dta”)
- Para el cierre de la preparación, precisar la ruta donde se deben almacenar la base de datos procesada y su extensión (p.ej. “input/data/original/proc-data.RData”)
- Para la ejecución de los análisis se debe precisar el origen de la base procesada que fue creada en el punto 2.
- Para los archivos de resultados provenientes del análisis de los datos, tales como figuras o tablas, debemos precisar la ruta donde se almacenarán y su nombre.
4.2.1.4 Resultados
Con los resultados, nos referimos a las figuras, gráficos o tablas que son producto de nuestro análisis y que serán relevantes de alguna forma para el estudio. Comúnmente, los protocolos para la organización de las carpetas proponen que todo lo que esté relacionado a los resultados se guarde en una carpeta aparte. Por ejemplo, el protocolo IPO propone albergar tablas y figuras en las subcarpetas tables e images dentro de la carpeta output.
Tomando como ejemplo el uso del protocolo IPO, sugerimos que para una correcta identificación de cada archivo se sigan las siguientes indicaciones:
Para las imágenes, sugerimos usar nombres breves e incorporar numeración. Por ejemplo “figura01.png”, según el orden de aparición en la publicación.
Para el caso de los cuadros o tablas, existen distintas extensiones para almacenarlas como archivos independientes (tex/txt/md/html/xls). Para ello, sugerimos emplear nombres cortos e incorporar numeración. Por ejemplo, “tabla01.xls”, según el orden de aparición en la publicación.
4.2.2 Texto plano y documentos dinámicos
Adoptar ciertas prácticas en lo que respecta a la estructura de un proyecto es el primer paso en el espectro de reproducibilidad. El segundo paso que proponemos acá es el uso de texto plano y documentos dinámicos.
Probablemente, el programa que más se ha utilizado para la escritura, desde la formación de pregrado hasta el trabajo cotidiano como investigador, sea Microsoft Word. Sin duda, es una herramienta sumamente útil, cuenta con varias funciones que permiten ordenar y hacer más estéticos nuestros documentos, no obstante, no es reproducible. Aunque Microsoft Word sea un formato de archivo ampliamente conocido, necesitamos algún tipo de lector asociado al formato .docx (u otro similar) para poder leer los archivos. Esto implica que solamente las personas que tengan instalado algún lector para este tipo de documentos serán capaces de acceder al contenido, lo cual va en contra de la idea de reproducibilidad.
Ahora, también es cierto que el formato de Word está tan extendido, que es realmente difícil que alguien no tenga disponible un lector de este tipo de archivos. Sin embargo, el real problema está con quien es dueño de ese contenido. Acá no nos inmiscuimos en temas de propiedad intelectual, pero sí es importante hacerse la pregunta sobre quién es dueño de lo que escribimos si el medio por donde estamos escribiendo no es propiedad nuestra. Es cosa de imaginarse que, de un día para otro, todo programa asociado a Microsoft desapareciera por alguna razón: todos nuestros documentos quedarían obsoletos. Aquí es donde entra el texto plano.
El texto plano es, simplemente, un tipo de texto que se puede leer independiente del lector que se use. Un ejemplo simple es escribir en el bloc de notas de Windows. El texto plano es importante cuando buscamos avanzar hacia la reproducibiliad por dos razones. Primero, es un tipo de texto universal, lo que da la ventaja de que, en principio, cualquier persona será capaz de leer algo escrito en este formato. Segundo, sienta las bases para que surjan lenguajes que permiten sofisticar el formato de los documentos, pero que sigan teniendo el carácter universal del texto plano. Los ejemplos más conoocidos son LaTeX y Markdown.
La descripción en detalle del lenguaje LaTeX y Markdown no son objetivo de este capítulo, pero sí es importante tenerlos en cuenta ya que han dado paso a una de las herramientas más utilizadas en la ciencia abierta: los documentos dinámicos. Estos son documentos que incluyen, a la par, texto plano y código. Es decir, ya no es necesario que utilicemos una hoja de código para generar un gráfico y luego pegarlo en un documento Word para escribir nuestro artículo, sino que podemos hacer todo esto en un mismo archivo. Además de hacer nuestro flujo de trabajo más eficiente, también hace más fácil reproducir los archivos. Por ejemplo, si quisiéramos que un colega revisara nuestro artículo, bastaría con que le enviáramos el documento dinámico que contiene tanto el código como el escrito. Así, él podría revisar la escritura del documento, y además, evaluar si los análisis han sido efectuados correctamente.
Las distintas formas de documentos dinámicos dependen del software que se vaya a emplear para la programación del código. Según Schindler et al. (2021), los softwares más usados en las ciencias sociales actualmente son R y Stata, por lo que presentaremos un resumen de sus respectivos formatos de documentos dinámicos: RMarkdown y Stata Markdown. También, Python ha sido indiscutiblemente uno de los lenguajes de programación más utilizados en el último tiempo y no solo por científicos sociales. Es por esto que también presentaremos su versión de documento dinámico: Jupyter Notebook.
RMarkdown
RMarkdown es un tipo de documento dinámico que combina código de R con lenguaje marcado tipo Markdown (para aprender a usar Markdown click aquí). En los documentos de RMarkdown, todo lo que escribamos en el documento, el software asumirá que está en formato Markdown, por lo que si utilizamos alguna de las marcas (e.g. usar negrita en alguna palabra) en el documento final esa marca se hará efectiva. Cuando queremos utilizar código debemos escribirlo en bloques o chunks. Los chunks de código tienen distintas opciones, solo por dar un ejemplo, podemos escribir un código para elaborar un gráfico, pero no queremos que se muestre el código que se utilizó para elaborar el gráfico, pues los chunks nos dan la opción para lograr eso. Caso contrario, si queremos mostrar tanto el gráfico como el código para elaborarlo -por ejemplo, para que alguien revise si hemos cometido algún error-, los chunks de código también tienen una opción para eso. En suma, podemos utilizar las distintas marcas de edición que nos ofrece Markdown, así como las distintas opciones para los chunks de código, con tal de elaborar un documento tal y como nosotros lo queremos. Para más información sobre RMarkdown, ver el enlace aquí.
La característica más importante de RMarkdown, es que la combinación del lenguaje marcado y el código se da en un documento renderizado. Renderizado significa que pasa por un proceso en el que se reconocen las distintas indicaciones de marcas y código, dando como resultado final un documento html, pdf o word. La herramienta encargada de este proceso es Pandoc, un convertidor de documentos universal (para más información ver: https://pandoc.org/)
Stata Markdown
Si bien en Stata han emergidos varios paquetes que buscan apoyar la elaboración de documentos dinámicos (e.g. ver aquí), el comando Markstat es quizás el más conocido. Al igual que otros tipos de documentos dinámicos, Markstat combina lenguaje Markdown con código de Stata, la principal diferencia con RMarkdown es que el código no se ejecuta en chunks, sino que está separado del texto plano con indentaciones. Es importante tener en cuenta que para ejecutar Markstat debemos tener instalado Pandoc. Para más información sobre cómo utilizar Markstat ver aquí.
Jupyter Notebook
Jupyter Notebook es un tipo de documento dinámico que combina lenguaje marcado tipo Markdown con código de Python. Al igual que RMarkdown, todo lo que escribamos en los Jupyter Notebook será considerado como lenguaje marcado. La diferencia que tiene con RMarkdown es que el documento va renderizando las marcas e indicaciones de código en tiempo real. Es decir, si escribimos en negrita, títulos de distinta jerarquía o añadimos gráficos o tablas el documento lo mostrará inmediatamente. Para más información sobre cómo utilizar Jupyter Notebook ver aquí.
4.2.3 Control de versiones
El control de versiones es la tercera herramienta para la reproducibilidad que queremos presentar. Esas son herramientas de software para gestionar los cambios en los documentos. ¿Alguna vez has utilizado Google Docs para trabajar colaborativamente? Pues, este es un ejemplo cotidiano del control de versiones. Google Docs permite rastrear quién hizo qué cambio y cuándo. Además, permite restaurar un documento de una versión anterior. Sin embargo, Google Docs no es tan útil cuando el trabajo que debemos realizar es programar código.
Para el control de versiones de códigos existen distintas herramientas, donde quizás la más conocida en el mundo de la programación es Git. Git es un sistema de control de versiones gratuito y abierto, tiene por objetivo hacer más eficiente el flujo de trabajo para proyectos grandes y pequeños. A la par existe Github, el cual es una plataforma colaborativa para el trabajo con código. Distintas disciplinas tanto de ingeniería y software, como relacionadas al ámbito científico utilizan Github como un centro de organización para el trabajo. Se utilizan repositorios, los cuales albergan todo lo relacionado a un proyecto, en el caso de la ciencia, a un proyecto de investigación.
Recomendamos el uso de Git y Github como flujo de trabajo para aquellos científicos sociales que trabajan con datos cuantitativos, especialmente cuando son grandes equipos de investigación o son proyectos con varias colaboraciones. Para más información sobre Git y Github ver aquí
4.2.4 Prácticas de código
Hasta ahora, hemos procurado que la presentación de la información sea lo más general posible y que no esté relacionada a un software estadístico único. Bajo esa idea, hemos presentado lo que es una estructura reproducible de un proyecto, aludiendo a los elementos comunes que se encuentran en distintos protocolos. También, revisamos cómo el control de versiones y el trabajo con documentos dinámicos pueden ser herramientas para la reproducibilidad. No obstante, no hemos abordado lo que, desde un principio, establecimos como el núcleo de la reproducibilidad: el trabajo con código.
Este capítulo busca ser una primera aproximación y enseñar lo básico respecto a reproducibilidad. Con tal de mantenernos bajo esa idea, trataremos el trabajo con código de forma abstracta, sin introducirnos a trabajar con un software en particular. Específicamente, veremos algunas prácticas de código que contribuyen a hacer un trabajo más reproducible. Estas son aplicables a distintos software que utilicen código y cuando nos estemos refiriendo a un software específico lo señalaremos.
Nunca hacer trabajo manual. El objetivo de la reproducibilidad es que cualquier persona pueda regenerar nuestro trabajo, y el trabajo manual es un obstáculo para el cumplimiento de ese objetivo. Trabajar con código permite automatizar los procesos de tratamiento y análisis de datos, es cómo establecer un guión paso a paso sobre lo que se ha hecho para llegar a los resultados del artículo, en contraste, documentar un proceso de análisis manual (e.g. en una planilla de datos) es una tarea sumamente compleja. Si bien es posible escribir un guión detallado de cada paso, esto tomaría una cantidad de tiempo y energía considerables, más aún teniendo en cuenta la cantidad de decisiones que tiene que tomar un equipo de investigación en el proceso de análisis de datos. Es por eso que la recomendación base es no hacer trabajo manual y trabajar con código, lo que implica evitar software como Microsoft Excel y otros relacionados.
Asegurarse que el código siempre produzca el mismo resultado. Nuestra hoja de código será la receta que otro seguirá para poder elaborar el mismo producto, por lo que tenemos que asegurarnos que esta produzca siempre lo mismo. Un ejemplo es cuando por algún tipo de análisis se necesitan generar números aleatorios. En R, para poder reproducir la generación de esos números aleatorios se utiliza la función
set.seed().Trabajar con scripts. Para poder automatizar el procesamiento y análisis de los datos, la principal recomendación es trabajar con documentos “script” que albergan el código y permiten su rápida ejecución. En el caso de R, se pueden utilizar documentos .R.
Escribir con minúscula, sin espacios, sin ñ y sin tildes. Gran parte de los software disponibles para análisis de datos traen el inglés como idioma nativo, por lo que existe una alta probabilidad de que tengamos problemas si utilizamos caracteres especiales que no se encuentran en ese idioma. Respecto al uso de mayúsculas, existen software que diferencian cuando un código incluye mayúsculas y cuándo no, esto es una característica conocida como case sensitive. Sin embargo, no todos los software cuentan con esta característica, por lo que es mejor evitar su uso.
Indentar el código. La indentación es una característica del trabajo con código en general (no solo a nivel de software estadístico) y se refiere a la jerarquía en los niveles del código. Indentar permite una lectura más fácil del código, ya que permite comprender visualmente el orden y la estructura del código. Uno de los ejemplos más conocidos es la elaboración de funciones condicionales de tipo
if-else.Comentar el código. Comentar el código es sustancial para que cualquier persona no asociada al proyecto (o incluso uno mismo en el futuro) pueda entender para qué sirve cada función y reproducir el documento sin problemas. Aquí el lema es: nunca es mucho cuando se refiere a comentar el código. Mientras mejor explicado esté qué hace cada cosa y por qué, la receta será más fácil de seguir.
Especificar las versiones de paquetes. Gran parte de los software estadísticos trabajan en base a la idea de paquetes. Estos son un conjunto de herramientas que facilitan el trabajo con datos. Existen paquetes tanto para tareas simples como el tratamiento de bases de datos o la generación de gráficos, así como para técnicas estadísticas avanzadas. No obstante, una característica a tener en cuenta es que los paquetes tienen versiones, ya que van mejorando día tras día. Esto ocurre especialmente en software de código abierto como R o Python. A raíz de esto, es que una de las recomendaciones para la reproducibilidad es conocer con qué versión de los paquetes se está trabajando y documentarlo. Inclusive, en software como R existen herramientas que permiten facilitar esta tarea (ver groundhog)
Elaborar código autocontenido. Existen dos formas de trabajar con código. La primera es el trabajo tipo “cascada”, donde el código es como agua que fluye desde arriba hacia abajo. Esta metáfora significa que cada código es parte de un todo interdependiente, y como tal, cada bloque depende del anterior. Un ejemplo simple es que con un bloque de código se carga una base de datos y con otro se presenta un gráfico de la misma. En contraste a esta forma de trabajo, existe una segunda de tipo “autocontenida”. Esta forma implica que, en vez de que el código sea interdependiente entre sí, cada bloque de código es una tarea que inicia y finaliza en el mismo bloque. Siguiendo el ejemplo, esto implicaría que cargar la base de datos y mostrar un gráfico de ella es una tarea que comienza y termina en el mismo bloque de código. Si bien el trabajar con código ya es un avance hacia la reproducibilidad, trabajar de manera autocontenida es un paso mucho mayor, ya que minimiza la probabilidad de que el código no pueda ser reproducido por un tercero.
Nombrar variables de manera óptima. Como se señaló anteriormente, muchas veces los nombres de las variables en las bases de datos siguen una lógica más técnica que sustantiva. Es por eso que, para poder trabajar de manera óptima y que, al mismo tiempo, el código sea más fácil de leer se sugiere renombrar las variables de forma sustantiva y corta. Por ejemplo, si una variable de edad de una encuesta tiene por nombre
m01, sugerimos cambiarlo aedad.Etiquetado o buen diccionario de variables. Además de renombrar las variables, recomendamos etiquetar de forma sustantiva las variables que se utilizarán y/o hacer un buen diccionario de ellas. Esto tiene por objetivo que la base de datos que hayamos elaborado para nuestros análisis sea más fácil de leer y reproducir.
Utilizar UTF8. Como señalamos, recomendamos evitar el uso de caracteres especiales en trabajo con código, esto implica el uso de tildes o ñ. No obstante, para ciertas situaciones será indispensable que escribamos en nuestro idioma nativo (en este caso español), y por ende utilizar caracteres especiales. Un ejemplo es cuando establecemos los títulos y categorías de una tabla o un gráfico. En estos casos, sugerimos establecer el formato del documento de código en formato UTF-8. Este formato es de tipo universal y acepta todo tipo de caracteres, incluyendo los especiales.
Trabajar con rutas relativas. Las rutas relativas son una ubicación en el computador que es relativa a un directorio base o carpeta raíz. En el caso del trabajo con datos, generalmente la carpeta raíz es la que alberga todos los documentos que refieren a ese proyecto y las rutas relativas son direcciones hacia distintos archivos teniendo como base la carpeta raíz. Esta es una forma reproducible de ordenar los archivos ya que no depende de quién está trabajando.
Uso de software libre. Con los nuevos avances en la tecnología y en el acceso a ella han emergido iniciativas colaborativas de desarrollo de software. Esto implica que en vez de estar centralizado por una compañía, quien está detrás de los avances en el desarrollo del software es una comunidad activa de usuarios. Software como R y Python son ejemplos de este tipo de iniciativas. Recomendamos el uso de software libre porque, además de alinearse con los principios de la ciencia abierta, proveen un ambiente y herramientas mucho más propenso a adoptar prácticas que avancen hacia la reproducibilidad.
Estar en contacto con la comunidad de investigadores y/o desarrolladores de herramientas computacionales. Más que una práctica relacionada al código, es una recomendación respecto a cómo hacer más óptimo nuestro trabajo. Con internet y las nuevas herramientas computacionales, existen varias comunidades a las cuales recurrir en caso de necesitar ayuda con el desarrollo del código. Por ejemplo, Stack Overflow es un foro donde programadores, ingenieros y en general cualquier persona que utiliza código en su día a día puede hacer o responder preguntas respecto a código. Es una gran herramienta para cuando los códigos no funcionan o cuando queremos conocer formas más eficientes de hacer una tarea. Incluimos esta recomendación porque participar de estos foros y ser parte activa de la comunidad implica adoptar prácticas para la reproducibilidad, con tal de que otros puedan entender nuestras preguntas y respuestas.