IPO
Input → Procesamiento → Output
Protocolo para flujo de investigación reproducible
IPO-es
IPO (Input-Procesamiento-Output) Protocolo para flujo de investigación reproducible
Para bajar un ejemplo de la estructura de carpetas click aquí.
Comentarios y sugerencias a juancastillov@uchile.cl
Esta es una plantilla/protocolo de carpetas de proyecto basada en el protocolo TIER (Integridad de Enseñanza en Investigación Empírica). TIER “promueve la integración de principios y prácticas relacionadas con la transparencia y la replicabilidad en el entrenamiento en investigación de los científicos sociales”. (más información en https://www.projecttier.org/).
La implementación de la reproducibilidad en este tipo de protocolos se basa en generar un conjunto de archivos auto-contenidos organizado en una estructura de proyecto que cualquier persona pueda compartir y ejecutar. En otras palabras, debe tener todo lo que necesita para ejecutar y volver a ejecutar el análisis.

El protocolo IPO sigue la lógica de TIER, pero con algunas innovaciones:
- intenta un modelo fácil de memorizar y relacionado con el flujo de trabajo de análisis (Input-Procesamiento-Output = IPO), donde el procesamiento se refiere a la preparación y análisis de datos.
- agrega una carpeta “Input”, que tiene un alcance más amplio que la carpeta “Datos” original en TIER, pero también otras posibles entradas, como imágenes externas y archivos de bibliografía.
- la carpeta de datos también se simplifica, incluyendo ahora solo una estructura “original” y “procesada”.
- modifica los archivos a .md/.qmd (archivos Quarto) en lugar de .txt. Markdown es un lenguaje de texto con marcas mínimas de formato que luego se pueden convertir a otros formatos como pdf y / o html (por ejemplo, cuando se usa R / Quarto). Pero, en el fondo, son simples archivos txt con solo otra extensión.
Archivos y estructura de carpetas
Para descargar un ejemplo de la estructura de carpetas del protocolo, haga click aquí.
La estructura se detalla en el siguiente esquema:
├── input: información externa como datos, imágenes, .bib
│ ├── data
│ │ ├── original → archivos de datos originales y metadatos disponibles
│ │ ├── proc → archivos de datos procesados
│ │ ├── imagenes
│ │ ├── bib → archivos de bibliografía
│ │ ├── prereg → archivos de pre-registro si están disponibles
│
├── procesamiento
│ ├── preparacion.qmd
│ ├── analisis.qmd
│
├── output: tablas, gráficos y otras salidas del procesamiento
│ ├── graphs
│ ├── tables
- readme.md → archivo general de introducción
- paper.md o paper.qmd / paper.html / paper.pdf → artículo / paperPrincipios básicos
- Orden: trabajar pensando en alguien que no esté familiarizado con el proyecto pueda entenderlo y reproducirlo sin mayores instrucciones que la referencia a este protocolo y otra información que esté en el archivo readme.md. O piense en usted dentro de 5 años: ¿podrá comprender y reproducir esto?
- Comentar los códigos: registrar brevemente los motivos de cualquier decisión.
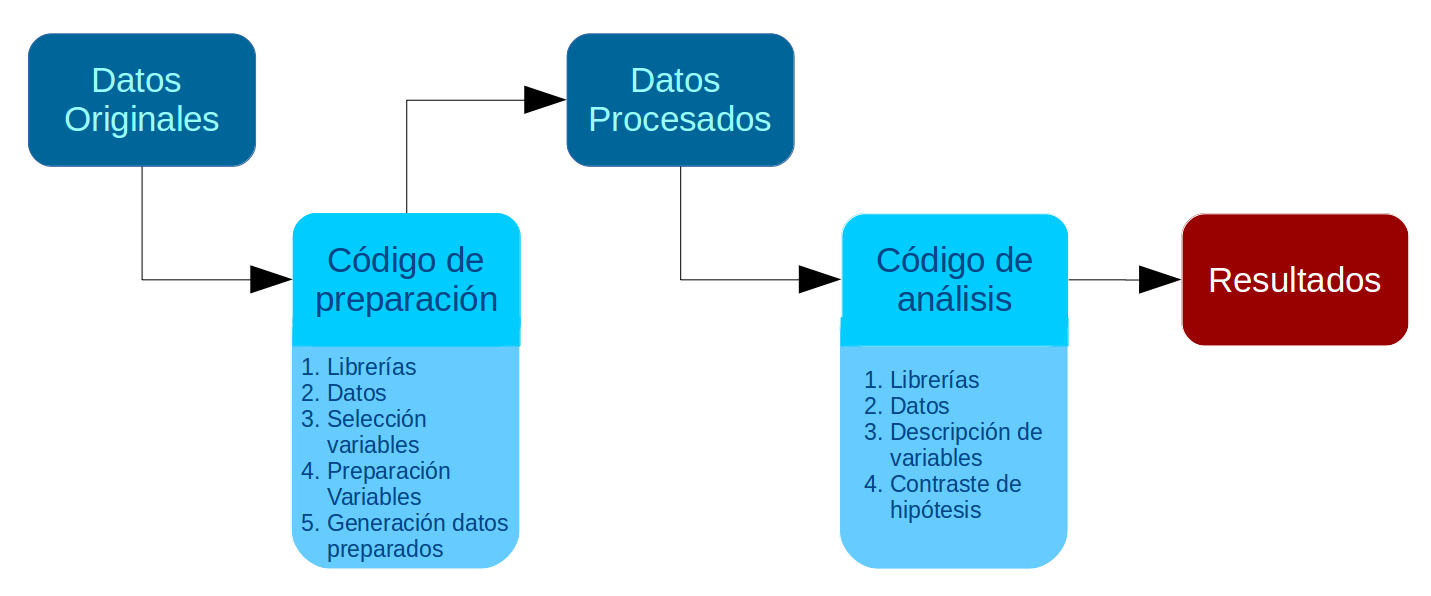
- el código de preparación debería comenzar cargando los datos originales y terminar guardando los datos procesados en la carpeta correspondiente (proc).
El flujo de trabajo asociado a estos principios se presenta en el siguiente esquema:
Ejemplo
Un ejemplo mínimo para probar la implementación del protocolo se puede bajar aquí
Notas
- Como el entorno R / Quarto permite combinar texto, análisis y resultados, las carpetas de procesamiento y output pueden resultar redundantes. Sin embargo, cuando se trabaja en un proyecto tipo artículo o tesis, es aconsejable separar input, procesamiento y output en aras del orden y la reproducibilidad.
- Para facilitar el trabajo en Rstudio, es posible que desee hacer de la carpeta del proyecto una carpeta Rproject.
- Además de tener una carpeta de proyecto donde está contenida toda la información, la clave técnica es usar rutas relativas.